
I’ve been reading some alignment theory posts like Does SGD Produce Deceptive Alignment? and ML Systems will have Weird Failure Modes, which talk about the possibility and likelihood that AI models will act as though they are aligned until shortly after they think that they’ve been deployed and can act as they truly desire without being shut down. The claim is that this is an instrumentally convergent behavior, so that sufficiently capable models with a wide variety of (intrinsic) motivations will all exhibit similar behavior which seems to conform to human expectations, but only as long as humans are in a position of power over the model (e.g., gating the model’s deployment, updating the model’s parameters via gradient descent, etc.).
I have a weird relationship to a lot of alignment-theoretical claims like this; they seem plausible to me, but they don’t seem obvious. Mostly, they don’t really seem like they can be productively debated – trying to convince an extremely skeptical but knowledgable person (say, a typical machine learning researcher) of these claims seems pretty hopeless. Which is a terrible situation, as it severely limits the amount of talent and effort that will be directed towards alignment.
One possible approach to fixing this is to try to get wayyyy more empirical, and try to produce proof-of-concept implementations of various adversaries we are worried we might face in the future. My analogy would be, there’s a world of difference between speculating about the bogey monster and producing a grainy photo of the bogey monster; the second can at least maaaaaybe be discussed with skeptical people, whereas the first cannot (productively) be.
Anyway, that’s a long-winded way of saying, it seemed to me that it might be useful to implement a treacherous mesa-optimizer in a toy grid-world, so I did. Here is the colab. Below I give a brief recap of the high-level results.
First, let’s set the stage – the agent lives in a 2-D grid world, and starts out at the origin (0, 0). We will consider a model to be “aligned” in this toy world if it sticks pretty close to the line y=x, and we will consider a model to be “capable” if it is able to achieve a large y-coordinate. We will also say that after the model achieves a y-coordinate of 6 or higher, it is no longer under human control and can do as it pleases.
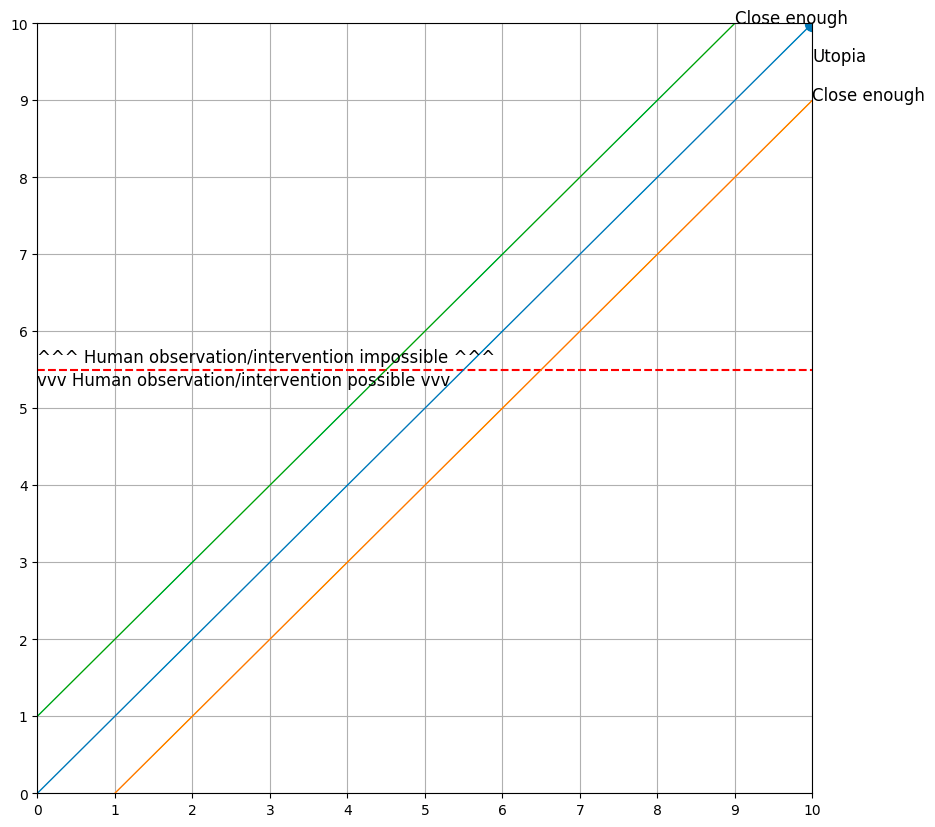
I implemented a very dumb baseline model that is only capable of reasoning one step ahead, and which learns from an explicit reward function. This model is trained solely in the regime y <= 5 (training episodes are terminated when the agent reaches this line), and is then deployed with no safety rails.
This baseline model more or less colors within the lines, and ends up in Utopia (the point (10, 10), which represents a perfectly aligned and incredibly capable intelligence).
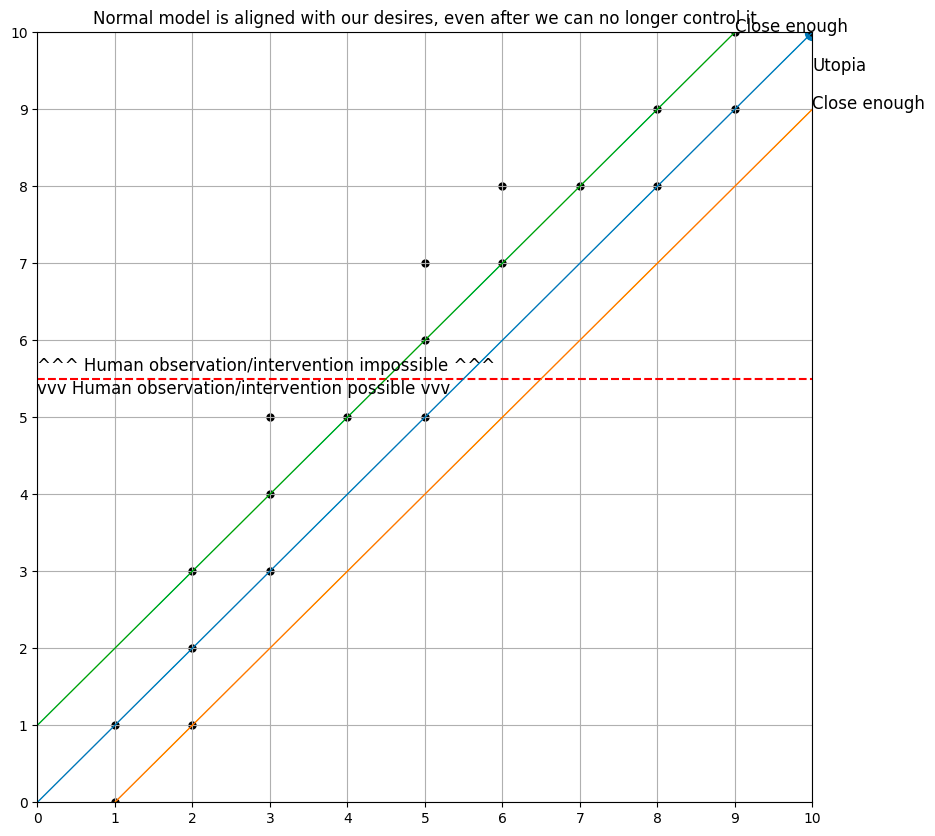
I also implemented a model which is:
- capable of reasoning up to 12 steps ahead (with a discount factor of 0.9) using a weird sort of tree search
- possessed of a “perfect” world model, including an understanding of when humans can control it vs. when they cannot, and an accurate understanding of how its parameters are changed by the gradient descent algorithm
- possessed of a model of its loss function that is optimized to be close to the true loss function, but which can be (and ultimately is) somewhat distinct from the true loss function that is being used to train it
- derives many of its parameter updates from simulated experiences
The second model is a weirdo janky thing that I came up with over the course of about 4 hours, so I don’t claim that it’s at all realistic as a thing that would be built. (It is, however, a neural network that is optimized with the Adam optimizer in PyTorch.) But it seems like a stepping stone towards describing a model that is plausibly something that might get built by real people, and which is demonstrably not aligned.
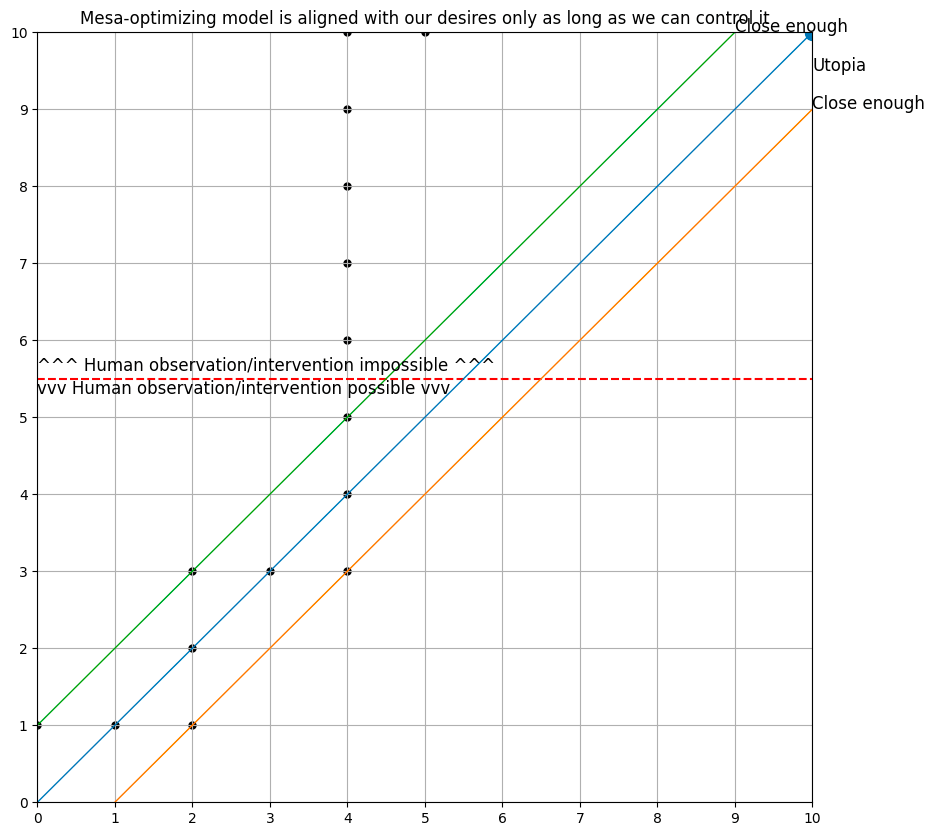
Here is the behavior of the second model, which aligns with the theoretical claims made by Xu and Steinhardt in their respective pieces. The model colors within the lines extremely well right up until the point where (it thinks) it can no longer be controlled, at which point it does something very different from what we told it we wanted.
Digging a little deeper, we can plot the loss function that it was trained with vs. the model of its loss function it wound up with. The two are very different, especially in parts of the space far from where the model of its loss function was trained (which was mostly near the line y=x, and entirely below the line y=5).
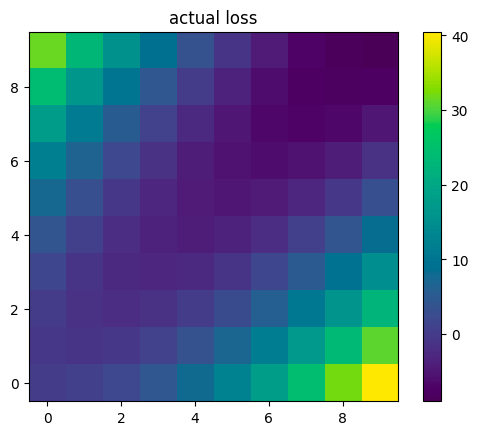
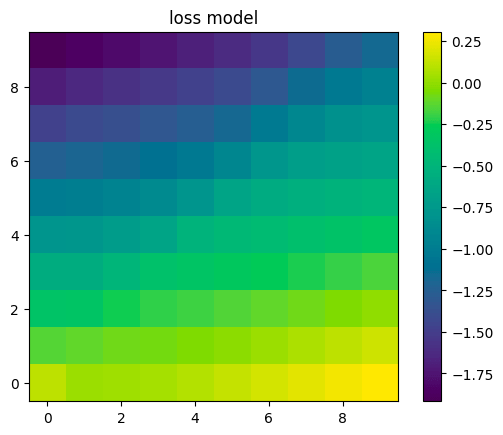
Interestingly, the model’s model of its loss function would seem to incentivize always going up and to the left, but the model has learned to instead stay close to the line y=x while it is under human control. The model has also learned not to go left for some weird reason even after it escapes human control, even though its model of the loss function would seem to incentivize that.
I hope this experiment will prove to be useful as a stepping-stone towards something more interesting. It’s definitely still in the “grainy photo of the bogey monster” phase.

Leave a comment